

| URL: | http://netzspannung.org/database/49008/de |
| Last update: | 30.06.2001 |
| Date of print: |
|
Technik
Technische Beschreibung
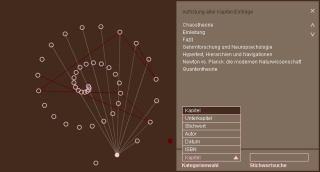
Die Systemarchitektur ist umgesetzt als "3-Tier Client/Server Modell" (3-stufiges Client/Server Modell). Prinzipiell verlangt es eine Trennung von Daten, Anwendungslogik und Darstellung. Die Vorteile sind unter anderem eine größere Flexibilität und bessere Performance durch Verteilung der Aufgaben. XML als Datenformat: Jeder Informationsbaustein ist eine physikalische Datei, welche die eigentliche Information, die Verknüpfungen und Meta-Daten enthält. Als Format für diese Dateien stellt XML die ideale Lösung dar. Da die gesamte geschriebene Arbeit in solchen Dateien abgespeichert ist, versehen mit Quellenangaben, Abbildungsreferenzen, Notizen, Angaben zur Reihenfolge usw. muss es möglich sein, die Daten gezielt wieder aus der großen Menge von Dateien zu extrahieren. Die einzelnen Daten müssen also mit semantischen Informationen versehen sein und das Format muss verlässliche Abfragemechanismen erlauben. Hier bieten sich hauptsächlich zwei Lösungswege an. Datenbanken oder Dateien im XML-Format (Es gibt inzwischen auch Datenbanken, die mit dem XML-Format arbeiten. Diese haben wir jedoch nicht betrachtet, da sich prinzipiell dieselben Nachteile ergeben würden, wie bei normalen Datenbanken s.u.). XML ist eine Metasprache für das Definieren von Dokumenttypen. Sie legt strikte Regeln fest, wie ein Dokument aufgebaut sein muss und wie Inhalte semantisch gekennzeichnet werden müssen. Verfasst werden können die Dokumente in einem normalen Texteditor. Die enthaltenen Daten werden durch sogenannte Tags (Etiketten) gekennzeichnet. Diese Tags haben denselben Aufbau wie die aus HTML bekannten Tags. Bei einer Quellenangabe kann der Autor zum Beispiel mit Muster, Max angegeben werden. Die Namen der Tags kann man frei definieren, XML stellt ein universelles Datenformat dar. Es ergibt sich eine übersichtliche und gut lesbare Form der Daten, die durch ihre strikte Syntax auch maschinenlesbar ist. Auf Datenbanken wird hier nicht näher eingegangen. Sie sind sicherlich für eine laufende Anwendung die leistungsfähigere, stabilere und sicherere Variante. Zum Verfassen der Inhalte einer ganzen Anwendung, wie ein umfangreiches Schriftstück, sind jedoch auch andere Faktoren von hoher Wichtigkeit, die uns letztendlich auch dazu veranlassten, XML-Dateien anstatt einer Datenbank zu verwenden: Die leichte und schnelle Editierbarkeit ohne aufwendige Vorarbeiten: keine Autoren-Tools müssen verwendet und programmiert werden, wie es bei einer Datenbank nötig wäre, sondern ein einfacher Texteditor genügt. Die leichte Handhabbarkeit: keine laufenden Server oder ähnliches, sondern einfaches ÷ffnen, Speichern usw. auf Dateiebene. Das schnelle globale Ändern: keine komplizierten SQL-Abfragen, sondern globales Ersetzen im Texteditor. Intuitivere Bearbeitung: keine relationale Datenbankstrukturen, sondern alle Daten auf einen Blick, beim Namen benannt (durch Tags). Unabhängigkeit: keine Serverinstallation nötig, sondern betrachten und editieren auf jedem Computer und Betriebssystem möglich, ohne weitere Installation von Anwendungsprogrammen. Java für die Logik: Um die Inhalte der XML-Dateien automatisch auslesen und auswerten zu können, bedarf es eines Mechanismus, der die XML-Syntax versteht, Syntaxfehler anzeigen und ihn in andere Formen übersetzen kann. Zum Beispiel mussten sämtliche Quellenangaben ausgelesen und für unser Quellenverzeichnis in Listenform ausgegeben werden. Es muss auch möglich sein, die Inhalte auszuwerten und Ergebnisse dieser Auswertung erneut in XML-Form weiterzugeben. Für die Darstellung der Kreise auf der Benutzeroberfläche muss eine Liste aller Informationsbausteine mitsamt ihrer Verknüpfungen generiert werden, die wiederum maschinenlesbar sein muss. In unserem Fall geschieht dies durch den Client, der die Visualisierung der Daten übernimmt. Hierzu ist generell jede Programmiersprache geeignet, die Dateien einlesen und ausgeben kann. In der Literatur wird seit einiger Zeit die "Hochzeit" von Java und XML gefeiert. Beide sind verbunden durch gemeinsame Eigenschaften wie zum Beispiel Plattformunabhängigkeit, offene Entwicklung, dezentrale Standardisierung usw., weshalb auch schon verschiedene Funktionsbibliotheken in Java verfasst wurden, die den Umgang mit XML vereinfachen. Die Tatsache, dass unsere Anwendung für das World Wide Web bestimmt ist, spricht ebenfalls für die Verwendung der portablen Programmiersprache Java, die durch Zusätze wie Servlets und JavaServer Pages (siehe nächster Abschnitt) eine optimale Unterstützung zur Anwendung im Internet bietet. Java entspricht also den Anforderungen. Es ist plattformunabhängig, webtauglich, "versteht und spricht" XML, ist zudem frei erhältlich und gut dokumentiert. Wir verwenden für den Prototypen das "Java 2 SDK (Software Development Kit), Standard Edition, Version 1.3" . Als Bibliothek zur Unterstützung von XML wird die "Java API for XML Processing (JAXP), Version 1.0.1" benutzt. Seit dem Beginn unserer Arbeit an dem Prototypen wurden in diesem Feld zwei neue Bibliotheken veröffentlicht bzw. bekannt. Dies ist zum einen die JAXP, Version 1.1 und zum anderen JDOM . JDOM stellt eine bessere und gewohntere (für Java-Entwickler) Einbindung von XML-Funktionalität zur Verfügung und ist aufgrund seiner Eigenschaften zu bevorzugen. JDOM ist gegenwärtig als Beta-Version 5 verfügbar (Stand 15.2.2001). Die ausführliche Dokumentation der erstellten Java-Klassen befindet sich ebenfalls in Anhang A, Abschnitt 2. JavaServer Pages als Schnittstelle zwischen Client und Logik: Das Back-End des Systems wäre somit fast vollständig definiert. Es fehlt nur noch eine Komponente, welche die Anfragen der Client-Anwendung annimmt, die Berechnung durch die Java-Klassen anstößt und die Ergebnisse der Berechnung an den Client zurückgibt. Sun bietet hierzu JavaServer Pages (JSP) an. JSP baut auf der Java Servlet Technologie auf, welche im Prinzip eine Erweiterung von normalen Web-Servern ist. Servlets ermöglichen eine effektive Client-Server Kommunikation (auf Basis des HTTP-Protokolls) und können zunächst als Ersatz für die weit verbreitete, inzwischen jedoch veraltete CGI-Technologie angesehen werden. JSP nutzt diese Erweiterung und erlaubt zudem eine "seitenweise" Programmierung wie bei normalen HTML-Seiten, im Gegensatz zur objektorientierten Programmierung von Klassen bei Servlets. Bereits am Kürzel ist erkennbar, dass JSP im selben Anwendungsgebiet wie die ebenfalls verbreitete ASP (Active Server Pages) Technologie von Microsoft operiert, nur basierend auf der Programmiersprache Java (im Gegensatz zu Visual Basic). Servlet-Klassen und JSP-Seiten erfordern einen sogenannten Container (übers.: Behälter), in dem sie ablaufen können. Dieser Container übernimmt das Anlegen der Objekte, die Zuteilung von Ressourcen, den Ablauf der Client-Anfragenbearbeitung und das Speichern permanenter Objekte. Er ist üblicherweise als eigenständiger Server oder als "Plugin", der sich in bestehende Webserver "einklinkt", realisiert. Die permanent im Container gespeicherten Objekte müssen die JavaBeans-Spezifikationen erfüllen. Eine weitere von Sun entwickelte Technologie, die das Erstellen wiederverwendbarer Komponenten ermöglicht . Die in Anhang A, Abschnitt 2 abgedruckten Klassen zur Verwaltung und Speicherung der XML-Dateien erfüllen diese Spezifikation. Als guter Entwicklungsserver hat sich bei der Arbeit die Referenzimplementation "Tomcat Version 3.1" erwiesen, eine Entwicklung des "Jakarta Projects" für die Java-Platform . Darin ablaufende JSP-Seiten, die für unsere Anwendung nötig sind, werden im Anhang A, Abschnitt 3 gezeigt. Es können nun also Anfragen des Clients über HTTP im XML-Format angenommen werden und auf gleichem Wege und im selben Format wieder beantwortet werden. Jetzt muss nur noch ein Client gefunden werden, der ebenfalls XML "spricht" und sich zur visuellen Darstellung der Anwendung auf dem Client (im Browser) eignet. Flash als Client: Aus der oben erwähnten Anforderung - die Unterstützung von XML - ergeben sich für die Technologie auf Client-Seite im Wesentlichen zwei Möglichkeiten: Sun's Java Applets oder die Flashtechnologie von Macromedia (Unterstützung von XML erst ab Version 5). Ein wichtiger Entscheidungsfaktor ist bei webbasierten Anwendungen immer die Verbreitung der benötigten Komponenten bei World Wide Web-Benutzern, also die Erreichbarkeit. Diese ist bei beiden der erwähnten Technologien nicht optimal. Zwar wird die ältere Version 1 des Java-Plugins von den meisten Browsern unterstützt, kommen neuere Java-Technologien zum Einsatz, wird ein Download des Java-Plugins Version 2 nötig. Die Installation desselben gestaltet sich zudem nicht sehr einfach für Benutzer, die wenig Erfahrung mit Computern besitzen. Die Verbreitung des Flash-Plugins wird von Macromedia selbst mit optimistischen 96.4% angegeben . Ob dies den Tatsachen entspricht, wagen wir jedoch zu bezweifeln. Zudem stellt sich bei genauerer Betrachtung der Studien heraus, dass die Verbreitung der neuesten Version 5 nur bei durchschnittlich ca. 40% liegt. Trotzdem kann man hieraus eine Tendenz der Benutzerakzeptanz ableiten. Flash ist bekannt und Benutzer werden einer Aufforderung zum Herunterladen der neuesten Version eher folgen, als der zum Herunterladen des Java-Plugins. Hinzu kommt, dass die Installation im Normalfall reibungslos abläuft und nicht viel Hintergrundwissen vom Benutzer abverlangt. Da sich aus der Analyse der Erreichbarkeit kein klarer Favorit ergab, entschieden wir uns aufgrund der besseren Performance bei der Darstellung grafischer Elemente und der einfacheren Erstellung von Applikationen, zur Anwendung der Macromedia Flash 5 Technologie, die sich seit ihrer Version 4 erheblich weiterentwickelt hat. Es ist in Teilbereichen nun möglich, objektorientiert zu programmieren, die Performance hat sich sehr verbessert und das Einlesen, Bearbeiten und Ausgeben von Daten im XML-Format wird unterstützt. Auf Details der technischen Umsetzung in Flash wird hier nicht weiter eingegangen.
Hardware / Software
Entwicklungsrechner: Win2000, 800Mhz, 128 MB Ram Software: Homesite4.5, Flash 5
Kontext
Hochschule / Fachbereich
Fachhochschule Furtwangen
Fachbereich Digitale Medien
Betreuer des Projekts
Prof. Dr. Günter Hentrich
Fachbereich Digitale Medien
Kommentar des Betreuers
|
|
| » http://www.m-phasize…haoticnavigation.html |
|
|